The investment strategy that I employ continues to produce consistent results. My asset allocation modelling exercise this year validated the current asset allocation in each of our portfolios and I do not propose to make any change.
Explanation of the relationship between risk and return
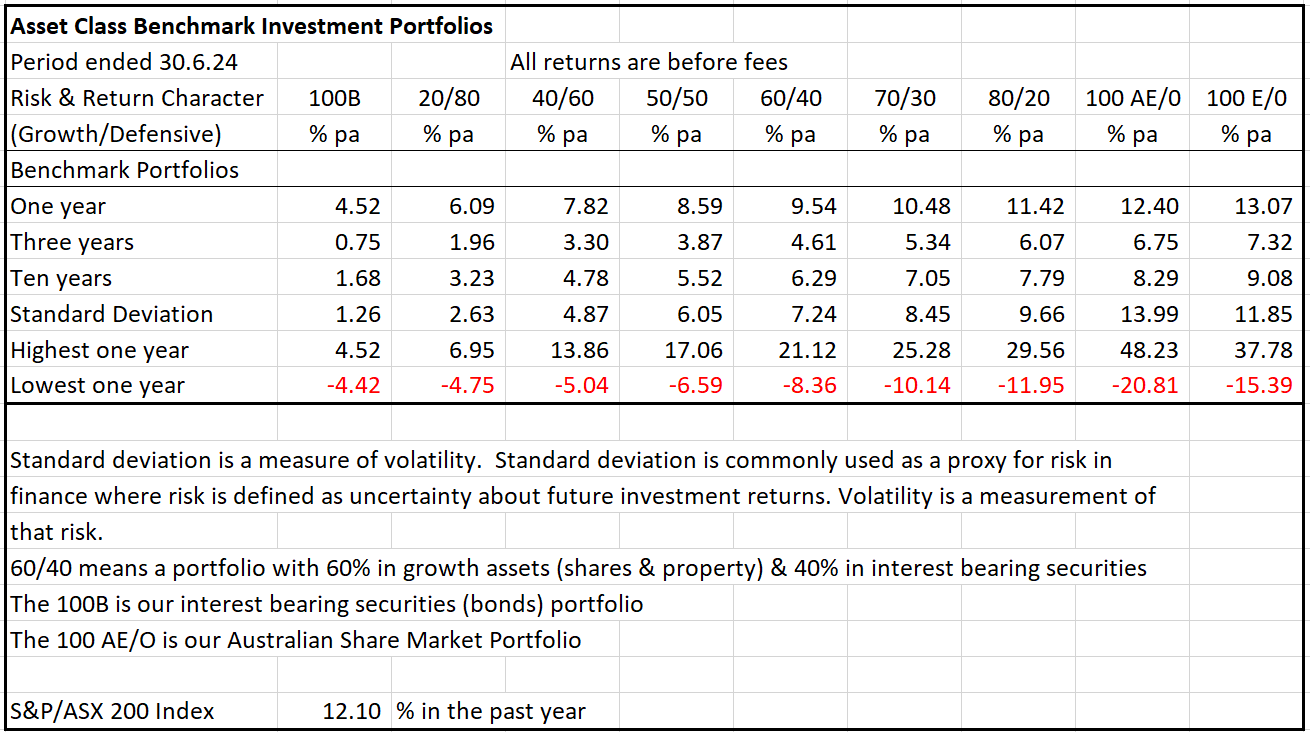
To give you an indicator of the investment experience that you would be likely to have with different risk profiles we can refer to the table that shows the past performance of my Asset Class investment portfolios.
The calculations in the table are based on a calculation of the monthly return of each investment over the year ended 30.6.24.
Investment portfolios are commonly described according to the ratio of growth assets to defensive assets. Thus a 60/40 portfolio has 60% in growth assets and 40% in defensive assets. This is a succinct way of describing the broad asset allocation and therefore the risk and return character of an investment portfolio. Generally shares and property are included in the growth component and interest bearing securities and cash are included in the defensive component.
Looking at the table, the 100B portfolio is a conservative portfolio with 100% in interest bearing securities (defensive assets). As you look at the different portfolios in the columns to the right of the 100B portfolio you will see that the percentage of each portfolio that is invested in growth assets increases as the percentage invested in defensive assets decreases.
This indicates that the portfolios to the right of the 100B column are taking increasing risk (because they are investing in higher amounts of growth assets). This is consistent with the increasing Standard Deviation (a measure of risk) that is shown in the table. In other words, as you increase exposure to growth assets you also increase risk.
An efficient investment portfolio captures the return of each asset class and the return therefore reflects the risk of the portfolio. By contrast an inefficient portfolio may produce a return that is lower than the return of each asset class (less than the market rate of return) and take risk that is higher than the risk of each asset class (higher than the market rate of risk). Such a portfolio has unrewarded risk, therefore it is not efficient.[1]
In the table, the risk (standard deviation) of each portfolio increases as you move to the right and the one year return also increases. This indicates that the higher amount of risk is rewarded with a higher return.
Also the gap between the highest one year and lowest one year return increases as you expose the portfolio to more growth assets. This illustrates the highest volatility that you would have experienced within the last 10 years in any of these portfolios.
These are efficient investment portfolios because they capture the return of each asset class and consistently provide an investment return that reflects the amount of risk (standard deviation) in each portfolio.
These portfolios carry very little credit risk (the risk of loss of capital or income through the failure of an investment). Their risk is largely in the amount of volatility.
[1]The return of each asset class (the market rate of return) is measured objectively by reference to the relevant index.